

Table of contents


No headings in the article.
Machines can predict the future, as long as the future doesn’t look too different from the past.
Applications of Machine Learning
Before we get started, here is a quick overview of what machine learning is capable of:
- Healthcare: Predicting patient diagnostics for doctors to review
- Social Network: Predicting certain match preferences on a dating website for better compatibility
- Finance: Predicting fraudulent activity on a credit card
- E-commerce: Predicting customer churn Biology: Finding patterns in gene mutations that could represent cancer
“Most of the knowledge in the world in the future is going to be extracted by machines and will reside in machines” — Yann LeCun, Director of AI Research, Facebook
How Do Machines Learn?
To keep things simple, just know that machines “learn” by finding patterns in similar data. Think of data as information you acquire from the world. The more data given to a machine, the “smarter” it gets.
But not all data are the same.Imagine you’re a pirate and your life mission was to find the buried treasure somewhere in the island. In order to find the treasure, you’re going to need sufficient amount of information. Like data, this information can either lead you to the right direction or the wrong direction. The better the information/data that is obtained, the more uncertainty is reduced, and vice versa. So it’s important to keep in mind the type of data you’re giving to your machine to learn.
Nonethless, after a sufficient amount of data is given, then the machine can make predictions. **Machines can predict the future, as long as the future doesn’t look too different from the past.
Machine “learns” really by using old data to get information about whats the most likelihood that will happen.** If the old data looks a lot like the new data, then the things you can say about the old data will probably be relevant to the new data. It’s like looking back to look forward.
“More data beats better models. Better data beats more data.” — Riley Newman
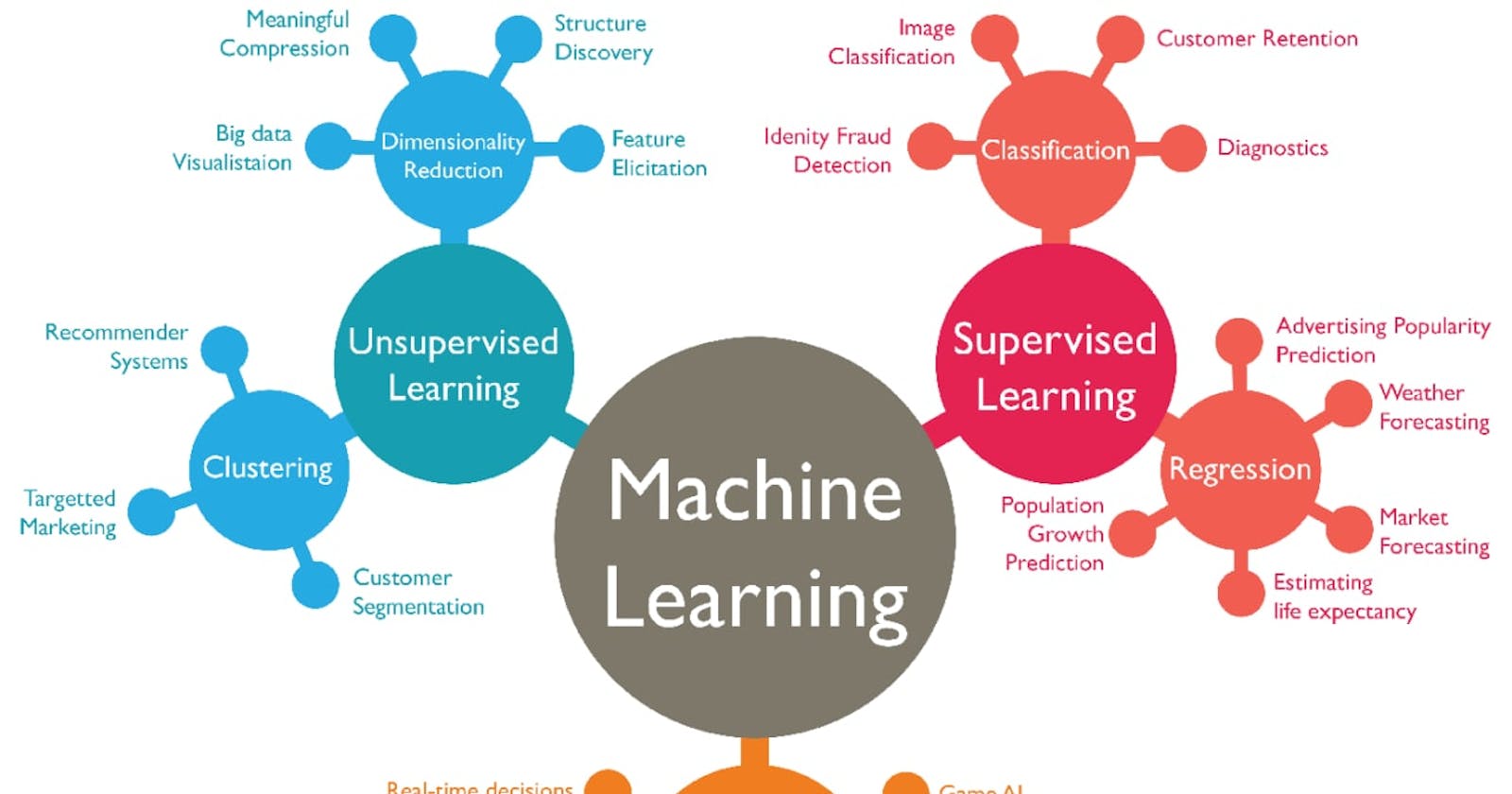
Types of Machine Learning
Important Definition (Label): In supervised learning, the “answer” or “result” portion of an example. Each example in a labeled data set consists of one or more features and a label. For instance, in a housing data set, the features might include the number of bedrooms, the number of bathrooms, and the age of the house, while the label might be the house’s price. in a spam detection dataset, the features might include the subject line, the sender, and the email message itself, while the label would probably be either “spam” or “not spam.”
There are three main categories of machine learning:
Supervised learning: The machine learns from labeled data. Normally, the data is labeled by humans.
Unsupervised learning: The machine learns from un-labeled data. Meaning, there is no “right” answer given to the machine to learn, but the machine must hopefully find patterns from the data to come up with an answer.
Reinforcement learning: The machine learns through a reward-based system.
Supervised Machine Learning
Supervised learning is the most common and studied type of learning because it is easier to train a machine to learn with labeled data than with un-labeled data. Depending on what you want to predict, supervised learning can used to solve two types of problems: regression or classification.
Regression Problem:
If you want to predict continuous values, such as trying to predict the cost of a house or the weather outside in degrees, you would use regression. This type of problem doesn’t have a specific value constraint because the value could be any number with no limits.
Classification Problem:
If you’re interested in a problem like: “Am I ugly?” then this is a classification problem because you’re trying to classify the answer into two specific categories: yes or no (in this case the answer is yes to the question above). This is also called a, binary classification problem.
Unsupervised Machine Learning
Since there is no labeled data for machines to learn from, the goal for unsupervised machine learning is to detect patterns in the data and to group them. Unsupervised learning are machines trying to learn “on their own”, without help. Imagine someone throwing you piles of data and says “Here you go boy, find some patterns and group them out for me. Thanks and have fun.”
Depending on what you want to group together, unsupervised learning can group data together by: clustering or association.
Clustering Problem:
Unsupervised learning tries to solve this problem by looking for similarities in the data. If there is a common cluster or group, the algorithm would then categorize them in a certain form. An example of this could be trying to group customers based on past buying behavior.
Association Problem:
Unsupervised learning tries to solve this problem by trying to understand the rules and meaning behind different groups. Finding a relationship between customer purchases is a common example of an association problem. Stores may want to know what type of products were purchased together and could possibly use this information to organize the placement of these products for easier access. One store found out that there was a strong association between customers buying beer and diapers. They deduced from this statement that males who had went out to buy diapers for their babies also tend to buy beer as well.
Reinforcement Machine Learning
This type of machine learning requires the use of a reward/penalty system. The goal is to reward the machine when it learns correctly and to penalize the machine when it learns incorrectly.
Reinforcement Machine Learning is a subset of Artificial Intelligence. With the wide range of possible answers from the data, the process of this type of learning is an iterative step. It continuously learns.
Examples of Reinforcement Learning:
- Training a machine to learn how to play (Chess, Go)
- Training a machine how to learn and play by itself
- Self-driving cars
Keep Learning new Stuffs Everyday! Happy Coding!
Follow me for more such blogs.